


Where Did SRE Come From – and What Does it Mean?
In 2003, Google’s Benjamin Treynor Sloss designed a new way for teams to run highly available, reliable, and serviceable production systems – a system now most commonly known as Site Reliability Engineering (SRE). Since its debut, SRE has risen in popularity globally among technology-focused organizations. The acronym has taken on two functional definitions:
-
Site Reliability Engineering – the concept
-
Site Reliability Engineer – the role
In this article, we will discuss Site Reliability Engineering as it pertains to both definitions and note the differences between the concept and the role as necessary. That said, the overall aim of this article is to discuss and clarify what SRE is, how it integrates and compliments Agile and DevOps approaches, common terms associated with SRE, and how SRE principles enable us to deliver great products and services to our customers.
The Technology Problems SRE Solves
Since the dawn of technology, those working in IT operations have been tasked with finding ways to make technology more reliable for the users who depend on it. Even the very best technology, when developed and presented on buggy/crash-prone/rigid/fragile infrastructure (take your pick), ends up frustrating users and ultimately failing to solve challenges as intended. Turns out, developing an effective technology solution is only part of the picture; it also has to run durably and reliably over the long term. SRE is one of the newest and most successful ways to combat these complex problems. It’s a back-to-basics approach to ensuring the reliable management of IT services from a coder’s perspective.
“SRE is what happens when you ask a software engineer to design an operations team.”
– Benjamin Treynor Sloss, Google
My Introduction to SRE
A Love Letter to ITIL
I started my career in IT as a network guy working with Banyan, Novell, and Microsoft. Since 2002, I have been working in the IT Service Management (ITSM) space, which from time to time had me working with IT service desks. This is how I came to know and love ITIL (version two at the time). As I am fond of saying, when I found ITIL, it was not so much like a lightbulb turned on, but rather an entire stadium was illuminated. Here was this brilliant framework that people had created based on their collective mistakes. They poured all of the black eyes and split lips earned from getting pummeled by IT failures into this expansive collection of lessons learned. It was truly illuminating – suddenly, we were able to do so much more, so much better. The ITSM framework forms some of the “basics” upon which SRE is built.
While, in terms of Service Management, ITIL remains my first love, I confess to jumping recklessly into flirtations, dalliances and even torrid affairs with as many other frameworks, standards, and BoKs (bodies of knowledge) as I could possibly find out there, so that we didn’t have to make (as many) mistakes ourselves, but rather learn from the works of others. In addition to ITIL, I have studied ISO/IEC 20000, MOF, and VeriSM and I bring content and insights from all of them into how I coach clients. Clearly, I am an evangelist for syncretism. “Adopt and adapt!” as I always say.
And this journey is the origin of my curiosity around SRE: Google says it is their approach to Service Management. I simply must know more and will share a summary of my findings below, starting with the role of a Site Reliability Engineer.
“Site Reliability Engineering is an emerging IT service management (ITSM) framework.”
(First line of Google’s SLO Adoption and Usage in Site Reliability Engineering report, published 1st April 2020)
The Role of a Site Reliability Engineer
What does a Site Reliability Engineer Do?
The role of SRE is multifaceted. When interviewed by Niall Murphy, himself an SRE, Ben Traynor, the VP of engineering at Google and founder of Google’s SRE concept, said the following:
“SRE is fundamentally doing work that has historically been done by an operations team but using engineers with software expertise and banking on the fact that these engineers are inherently both predisposed to, and have the ability to, substitute automation for human labor.
In general, an SRE team is responsible for availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning. Typically, we hire about a 50-50 mix of people who have more of a software background and people who have more of a systems background. It seems to be a really good mix.”
Site Reliability Engineer Salaries and Increasing Popularity
The rapidly increasing demand for SRE roles demonstrates consistent growth – with zero signs of decline. In January of 2019, LinkedIn ranked Site Reliability Engineer as the second most promising job in the US (Data Scientist being the first) with these statistics:

Site Reliability Engineer Salaries and Increasing Popularity
And a few more interesting statistics on the popularity of SRE as a job role:
- Site Reliability Engineer was the fifth-fastest-growing IT role in 2020 according to LinkedIn.
- I recently did a highly scientific Google search and found over 10,000 SRE jobs in the United States, with most paying over $100,000.
- Robert Half reported that SRE is one of the few IT roles in which the practitioner may earn more than the manager.
Safe to say that for those who find SRE concepts interesting, becoming an SRE is an extremely viable and in-demand career path with several books, professional organizations, and conferences supporting the growing field.
SRE and Its Relationship to Agile and DevOps
Many people who write about SRE as a concept tend to put it on a continuum beginning with having an Agile mindset and approach, incorporating and including DevOps concepts, and adding SRE concepts as the capstone to this spectrum.

The thinking often goes something like this:
- Agile is all about modern code development. Yes, I know we can apply Agile to many, many other types of work that have nothing to do with coding, but this is how it was first conceived. This fail-fast/learn and recover-faster mindset is an effective way to keep up with the constantly changing states of business and our customers’ needs and desires. An Agile mindset and approach is a good foundation upon which to build.
- DevOps was created, in part, to solve the issue of developers simply chucking work “over the fence” to their frenemies in operations, who are then tasked to support whatever technology has been thrown at them. Incorporating DevOps practices can help us drive collaboration and continuous delivery between these two often contentious groups that heavily rely on one another. While DevOps can drive real innovation for many organizations, bridging this divide remains challenging.
- SRE practices can serve as a form of completion, not competition, to Agile and DevOps ideas. Because of its focus on preparing for failures in production, SRE guidance provides that otherwise-missing foundation upon which developers can build a software engineering mindset into system administration and operations support.
It was this “focusing on preparing for failures in production” that made me think about the practices in IT Service Management like Incident, Event, and Problem Management, in particular.
SRE and Its Relationship with ITSM
While there is no shortage of SRE-related content out there, Google quite literally wrote the definitive books on SRE, namely:
- Building Secure & Reliable Systems (Available for download)
- The Site Reliability Workbook
- Site Reliability Engineering
The third book, Site Reliability, How Google Runs Production Systems (which we will refer to as “the book” in the remainder of this article), is not your average tech manual. It’s actually a collection of essays, musings even, written by many of the chief contributors to SRE. I may never say this about another technical manual ever again, but this book is a very enjoyable read. I will go so far as to say that at times, it is almost philosophical.
IT Service Management concepts are defined by a combination of 5 core ITIL 4 publications and 34 supplementary Practice Guides, which you can access through AXELOS’ MyITIL program.
While both ITIL and SRE provide countless ideas, templates, and recommendations for delivering value, they do so at different levels and from different perspectives. The ITIL library advises technology leaders and practitioners on what to do in providing products and services to customers, taking a strategic approach to incorporating the tactical point of view. SRE resources, on the other hand, tend to provide specific recommendations on how to do work at the system level, focusing heavily on the operational and tactical aspects of managing IT.
SRE’s Key Principles and Descriptions
Site Reliability Engineering recognizes seven key principles:
Principle |
Description |
Embracing Risk
|
Risk will always be with us. SRE guidance seeks to specifically balance out the risk the business feels it can accept with the inherent risk attached to a service. This is where SRE brings in one of its most important ideas – the Error Budget. The main benefit of an error budget is that it provides a common incentive that allows both product development and SRE to focus on finding the right balance between innovation and reliability.
|
Service Level Objectives (SLOs)
|
SRE guidance posits that Service Level Agreements (SLAs), are too reactive and prone to responding to a failure after it has occurred. SLOs, on the other hand, provide engineers with the performance objectives needed to get ahead of the failures before they occur.
|
Eliminating Toil or “Waste”
|
People are better served spending their time on long-term, higher-value engineering project work rather than on low value, operational work. Because the term operational work may be misinterpreted, the SRE books use a specific word: toil. Automation is the SRE’s go-to solution for eliminating toil.
|
Monitoring Distributed Systems
|
Monitoring and alerting enables a system to tell us when it’s broken and/or what’s about to break. When the system isn’t able to automatically fix itself, SRE guidance recommends a human investigate the alert, determine whether there’s a real problem at hand, mitigate the problem, and determine its root cause.
|
The Evolution of Automation at Google
|
Automation doesn’t just provide consistency. Designed and done properly, automatic systems also provide a platform that can be extended, applied to more systems, and even spun out for profit. The alternative – not having any automation – is neither cost effective nor extensible: it is instead a tax levied on the operation of a system (or what many call “technical debt”).
|
Release Engineering |
Release engineering is a relatively new and fast-growing discipline of software engineering that allows for rapid building and delivering of software. Release engineering is a specific job function at Google. Release engineers work with software engineers (SWEs) in product development and with SREs to define all of the steps required to release software—from how the software is stored in the source code repository, to how rules are built for compilation, to how testing, packaging, and deployment are conducted.
|
Simplicity
|
The SRE books, similar to phrasing within the Agile Manifesto, emphasize that simplicity is the height of elegance. This quote opens the chapter on Simplicity: “The price of reliability is the pursuit of the utmost simplicity.”
|
Source: C.A.R. Hoare, Turing Award lecture
A Deeper Dive into SRE’s Principles and ITSM Concepts
SRE does not spend much time at all concentrating on the needs, wants, or desires of customers, users, or stakeholders. This, however, is where ITIL 4 shines, with its strategic view of co-creating value with the customer. Let’s recall the quote from Ben Treynor Sloss, one of Google’s visionaries who was there from the start of the SRE movement, that opened this article: “SRE is what happens when you ask a software engineer to design an operations team.” SRE as a discipline is completely, maniacally, and even elegantly focused on IT operations (which aligns with ITIL 4’s most important guiding principle, Focus on Value) and how to deliver quality code quickly. The role and concept of SRE will certainly benefit from the ITIL 4 framework’s focus squarely on customers and their perception of what is or is not valuable.
The sections below provides a deeper dive into the key concepts and definitions in each of the principles and captures the differences and similarities between SRE and IT Service Management concepts in the ITIL 4 books and supporting references.
Embracing Risk
SRE Principle:
It is so important to the nature of SRE that they begin this list of principles with risk. Risk is everywhere and can never be removed from the equation entirely. Rather is must be lived with and managed. Here is a quote from the Site Reliability Engineering book that really sums up the point of view.
In SRE, we manage service reliability largely by managing risk. We conceptualize risk as a continuum. We give equal importance to figuring out how to engineer greater reliability into Google systems and identifying the appropriate level of tolerance for the services we run. Doing so allows us to perform a cost/benefit analysis to determine, for example, where on the (nonlinear) risk continuum we should place Search, Ads, Gmail, or Photos. Our goal is to explicitly align the risk taken by a given service with the risk the business is willing to bear. We strive to make a service reliable enough, but no more reliable than it needs to be. That is, when we set an availability target of 99.99%, we want to exceed it, but not by much: that would waste opportunities to add features to the system, clean up technical debt, or reduce its operational costs. In a sense, we view the availability target as both a minimum and a maximum. The key advantage of this framing is that it unlocks explicit, thoughtful risk taking.
This principle goes back to that notion of “focusing on preparing for failures in production.” SRE not only understands that risk is a constant but uses Jujitsu to turn risk into a virtue. When SRE sets that Availability target at 99.99%, the intention is to meet it but not exceed it too much – the goal is to leave room for experimentation and with it, potential failure. Not a lot of failure, just enough for that thoughtful risk taking mentioned above.
SREs are encouraged to accept failure as normal. They manage this philosophy with:
- Having SLOs (which we will define below)
- Blameless Postmortems (see below)
- Live and die by the Error Budget
ITSM Commentary:
Those working in IT Service Management should know that risk is inherent in all of the work we do. In fact, the ITIL 4 library has an entire practice devoted to Risk Management. The nature of risk and risk management are also key drivers and motivations of most other ITIL practices as well. However, I admire SRE’s front and center approach to Risk Management.
ITIL 4 also has its own Availability Management Practice. That practice defines Availability as: The ability of an IT service or other configuration item to perform its agreed function when required.
I began by trying to make a list of which of the 34 ITIL practices had a key focus on managing risk. But, I quickly concluded that it was easier to list those where risk is not a consideration (and it was a stretch to find one). In addition to ITIL practices,
ITIL 4’s Guiding Principles The ITIL 4 Guiding Principles of Think and Work Holistically and Progress iteratively with feedback also prompt us to maintain a focus on risk.
The ITIL 4 framework includes Risk Management among its General Management Practices. Not unlike SRE, ITIL 4’s Risk Management focuses on balancing Risk Capacity with Risk Appetite. The ITIL 4 Risk Management Process Guide describes these two concepts as:
- The risk capacity of an organization is the maximum amount of risk that the organization can tolerate and is often based on factors such as damage to reputation, assets, and so on.
- The risk appetite of an organization is the amount of risk that the organization is willing to accept. This should always be less than the risk capacity of the organization
The Error Budget
SRE Principle:
The embrace of risk means permission to fail, within bounds. SRE has us define and agree on an allotment of acceptable failure and place it in a budget to “spend” on activities such as innovation, new features or retiring technical debt. To explain this concept, I am going to quote directly from the again:
In order to base these decisions on objective data, the two teams jointly define a quarterly error budget based on the service’s service level objective, or SLO (more on this concept in a moment). The error budget provides a clear, objective metric that determines how unreliable the service is allowed to be within a single quarter. This metric removes the politics from negotiations between the SREs and the product developers when deciding how much risk to allow.
Our practice is then as follows:
- Product Management defines an SLO, which sets an expectation of how much uptime the service should have per quarter.
- The actual uptime is measured by a neutral third party: our monitoring system.
- The difference between these two numbers is the “budget” of how much “unreliability” is remaining for the quarter.
- As long as the uptime measured is above the SLO—in other words, as long as there is error budget remaining—new releases can be pushed.
For example, imagine that a service’s SLO is to successfully serve 99.999% of all queries per quarter. This means that the service’s error budget is a failure rate of 0.001% for a given quarter. If a problem causes us to fail 0.0002% of the expected queries for the quarter, the problem spends 20% of the service’s quarterly error budget.
In SRE, teams collectively set their own error budget, based on their own appetite for risk. The have a lot of autonomy so long as they meet their SLOs. This approach also extends to Change Management (What ITIL 4 calls Change Enablement). The idea is that you don’t need a Change Advisory Board (CAB) or Change Authority to slow work down if SREs are properly managing risk and do not breach that all important SLO. So long as the changes they are implementing do not impact the SLOs for the service, there is no need to scrutinize them. In this way, SRE is essentially giving the team to power to define their own Standard Changes. This approach allows SREs to instead find creative ways to automate changes.
ITSM Commentary:
This approach to managing an error budget is an entirely new way to look at risk for me. I find this principle fascinating. Most of IT Service Management, and ITIL in particular, emphasize governance and systems of control; and it’s a key part of ITIL 4’s concept of the Service Value System.
But the SRE principle is quite different here. SRE guidance emphasizes having self-regulating teams. Teams are expressively encouraged to make their own decisions, so long as the trains run on time. This means that everyone up and down the service line are held accountable to the SLOs for the service in question. To keep developers from inflating the Error Budgets with too much cushion, teams in operations and support have to agree to the amount of budgeted wiggle room as well. They are all on the hook together.
When they do exceed their Error Budget, there are consequences up and down the line. If the failure is severe enough or we burn though the Error Budget too far, all releases may be called to a halt, from developers to operations and support until they figure out what went wrong and how to make it right again. And this notion of the Error Budget is the score card that lets everyone know how they are performing.
Again, the SRE books emphasize the power of self-regulating teams. In this case, teams have the power to define and implement their own Standard Changes and subsequent automation to deliver them. So long as these Standard Changes don’t cause any negative impact on the SLOs, these teams are encouraged to innovate as they see fit. The removes decision makers who are further away from the change and pushes empowerment to the responsible teams.
This principle, by inference, falls right in line with the ITIL 4 guiding principle Optimize and Automate. This concept of the Error Budget is something that’s missing from the ITIL 4 framework and is a great addition.
Service Level Objectives
SRE Principle:
For those of us coming from an ITIL-centric view of ITSM, SRE’s emphasis on Service Level Objectives, SLOs, is quite interesting. Once again, a quote from the book speaks for itself:
It’s impossible to manage a service correctly, let alone well, without understanding which behaviors really matter for that service and how to measure and evaluate those behaviors. To this end, we would like to define and deliver a given level of service to our users, whether they use an internal API or a public product.
We use intuition, experience, and an understanding of what users want to define service level indicators (SLIs), objectives (SLOs), and agreements (SLAs). These measurements describe basic properties of metrics that matter, what values we want those metrics to have, and how we’ll react if we can’t provide the expected service. Ultimately, choosing appropriate metrics helps to drive the right action if something goes wrong, and also gives an SRE team confidence that a service is healthy.
To SRE, the SLOs are the objectives themselves, not the requirements behind them. The creation of SLOs is all in support of reliability.
SLIs measures the indicators that, individually and collectively, roll up to depict the health of the objectives:
- Hardware
- Software
- Infrastructure
- Cloud
- Environments
ITSM Commentary:
The ITIL 4 library has a practice devoted to Service Level Management (SLM) with special attention paid to the SLA, the Service Level Agreement. In this regard, ITIL 4 has a lot in common with this SRE principle.
Where the two concepts differ is that SRE authors feel SLAs have become more of a reactive, historical document, capturing where teams have failed. SRE guidance sees the SLO as its better, more proactive option that focuses on where we can get ahead of failures.
In terms of ITIL 4 guiding principles, this SRE principle aligns with Progress iteratively with feedback, Think and work holistically, and Collaborate and promote visibility.
Since SRE may use these terms a bit differently from standard ITSM usage, some definition is in order. From the Site Reliability Engineering book:
- SLI: An SLI is a service level indicator—a carefully defined quantitative measure of some aspect of the level of service that is provided. Most services consider request latency—how long it takes to return a response to a request—as a key SLI. Other common SLIs include the error rate, often expressed as a fraction of all requests received, and system throughput, typically measured in requests per second. The measurements are often aggregated: i.e., raw data is collected over a measurement window and then turned into a rate, average, or percentile. Another kind of SLI important to SREs is availability, or the fraction of the time that a service is usable.
- SLO: An SLO is a service level objective: a target value or range of values for a service level that is measured by an SLI. A natural structure for SLOs is thus SLI ≤ target, or lower bound ≤ SLI ≤ upper bound. For example, we might decide that we will return Shakespeare search results “quickly,” adopting an SLO that our average search request latency should be less than 100 milliseconds.
- SLA: Finally, SLAs are service level agreements: an explicit or implicit contract with your users that includes consequences of meeting (or missing) the SLOs they contain. The consequences are most easily recognized when they are financial—a rebate or a penalty—but they can take other forms. An easy way to tell the difference between an SLO and an SLA is to ask “what happens if the SLOs aren’t met?”: if there is no explicit consequence, then you are almost certainly looking at an SLO.
Eliminating Toil
SRE Principle:
In Site Reliability Engineering, the elimination of toil not only makes our work more fulfilling and less about drudgery but it also, through automation, makes it more efficient and more effective because we’re spending more time on impactful, high-value work.
Toil is not just “work I don’t like to do.” It’s also not simply equivalent to administrative chores or grungy work. Preferences as to what types of work are satisfying and enjoyable vary from person to person, and some people even enjoy manual, repetitive work. There are also administrative chores that have to get done, but should not be categorized as toil: this is overhead.
Overhead is often work not directly tied to running a production service, and includes tasks like team meetings, setting and grading goals,19 snippets,20 and HR paperwork. Grungy work can sometimes have long-term value, and in that case, it’s not toil, either. Cleaning up the entire alerting configuration for your service and removing clutter may be grungy, but it’s not toil.
So what is toil? Toil is the kind of work tied to running a production service that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows. Not every task deemed toil has all these attributes, but the more closely work matches one or more of the following descriptions, the more likely it is to be toil:
Manual:
- This includes work such as manually running a script that automates some task. Running a script may be quicker than manually executing each step in the script, but the hands-on time a human spends running that script (not the elapsed time) is still toil time.
Repetitive:
- If you’re performing a task for the first time ever, or even the second time, this work is not toil. Toil is work you do over and over. If you’re solving a novel problem or inventing a new solution, this work is not toil.
Automatable:
- If a machine could accomplish the task just as well as a human, or the need for the task could be designed away, that task is toil. If human judgment is essential for the task, there’s a good chance it’s not toil.
Tactical:
- Toil is interrupt-driven and reactive, rather than strategy-driven and proactive. Handling pager alerts is toil. We may never be able to eliminate this type of work completely, but we have to continually work toward minimizing it.
No enduring value:
- If your service remains in the same state after you have finished a task, the task was probably toil. If the task produced a permanent improvement in your service, it probably wasn’t toil, even if some amount of grunt work—such as digging into legacy code and configurations and straightening them out—was involved.
O(n) with service growth:
- If the work involved in a task scales up linearly with service size, traffic volume, or user count, that task is probably toil. An ideally managed and designed service can grow by at least one order of magnitude with zero additional work, other than some one-time efforts to add resources.
ITSM Commentary:
Once again, while ITSM as a discipline applauds this principle, only the High-Velocity IT publication calls it out and does not go into as much detail or as directly as in the SRE books. In terms of ITIL 4 guiding principles, Keep it simple and practical and Optimize and automate apply most directly.
To the SRE books, automation is king. As Carla Geisser, a Google SRE, says, “If a human operator needs to touch your system during normal operations, you have a bug. The definition of normal changes as your systems grow.” Another way to look at Carla’s quote is if you have to do the same thing twice, look for an opportunity to automate it. This might even include reducing or eliminating meetings when a Slack Channel might do just as well. Again, automation is an SRE’s go-to solution for the relief of toil.
Even with all of this elimination of toil, good SREs are never afraid of automating themselves out of a job. They know that because absolutely nothing is static in IT, there will always be something else to improve through automation and toil reduction.
While ITIL only puts some focus on the term toil, it does advocate for simplifying and automating these human tasks. This approach may not eliminate drudgery, but it can help eliminate human error.
Monitoring Distributed Systems
SRE Principle:
If the SRE discipline concentrates on focusing on preparing for failures in production, then Monitoring Distributed Systems is at the very core of these activities. Without monitoring, there is no way to get ahead of the failures before they occur.
The SRE books value the Four Golden Signals of monitoring: latency, traffic, errors, and saturation. If you can measure on four metrics, it’s vital to focus on these:
Latency:
- The time it takes to service a request. It’s important to distinguish between the latency of successful requests and the latency of failed requests. For example, an HTTP 500 error triggered due to loss of connection to a database or other critical backend might be served very quickly; however, as an HTTP 500 error indicates a failed request, factoring 500s into your overall latency might result in misleading calculations. On the other hand, a slow error is even worse than a fast error! Therefore, it’s important to track error latency, as opposed to just filtering out errors.
Traffic:
- A measure of how much demand is being placed on your system, measured in a high-level system-specific metric. For a web service, this measurement is usually HTTP requests per second, perhaps broken out by the nature of the requests (e.g., static versus dynamic content). For an audio streaming system, this measurement might focus on network I/O rate or concurrent sessions. For a key-value storage system, this measurement might be transactions and retrievals per second.
Errors:
- The rate of requests that fail, either explicitly (e.g., HTTP 500s), implicitly (for example, an HTTP 200 success response, but coupled with the wrong content), or by policy (for example, “If you committed to one-second response times, any request over one second is an error”). Where protocol response codes are insufficient to express all failure conditions, secondary (internal) protocols may be necessary to track partial failure modes. Monitoring these cases can be drastically different: catching HTTP 500s at your load balancer can do a decent job of catching all completely failed requests, while only end-to-end system tests can detect that you’re serving the wrong content.
Saturation:
- How “full” your service is. A measure of your system fraction, emphasizing the resources that are most constrained (e.g., in a memory-constrained system, show memory; in an I/O-constrained system, show I/O). Note that many systems degrade in performance before they achieve 100% utilization, so having a utilization target is essential. In complex systems, saturation can be supplemented with higher-level load measurement: can your service properly handle double the traffic, handle only 10% more traffic, or handle even less traffic than it currently receives? For very simple services that have no parameters that alter the complexity of the request (e.g., “Give me a nonce” or “I need a globally unique monotonic integer”) that rarely change configuration, a static value from a load test might be adequate. As discussed in the previous paragraph, however, most services need to use indirect signals like CPU utilization or network bandwidth that have a known upper bound. Latency increases are often a leading indicator of saturation. Measuring your 99th percentile response time over some small window (e.g., one minute) can give a very early signal of saturation. Finally, saturation is also concerned with predictions of impending saturation, such as “It looks like your database will fill its hard drive in 4 hours.”
Observability is becoming a very important concept within SRE as an even more proactive way to conceive of and leverage monitoring.
ITSM Commentary:
Here SRE and ITSM concepts are in agreement. ITIL 4 has specific practice for Monitoring and Event Management. The ITIL framework also advises that when looking at the Service Level Management and Availability Management publications, these practices have the obligation to monitor systems and services for agreed levels of quality paraments.
ITIL 4 guidance takes a different, somewhat higher-level approach in the Monitoring and Event Management publication than does SRE. The ITIL 4 publications call out three PSFs (Practice Success Factors) to direct these efforts.
- Establishing and maintaining approaches/models that describe the various types of events and monitoring capabilities needed to detect them.
- Ensuring that timely, relevant, and sufficient monitoring data is available to relevant stakeholders.
- Ensuring that events are detected, interpreted, and if needed acted upon as quickly as possible.
ITIL 4 guidance also sees a quadrant relationship between activities that are:
- Passive
- Active
- Proactive
- Reactive
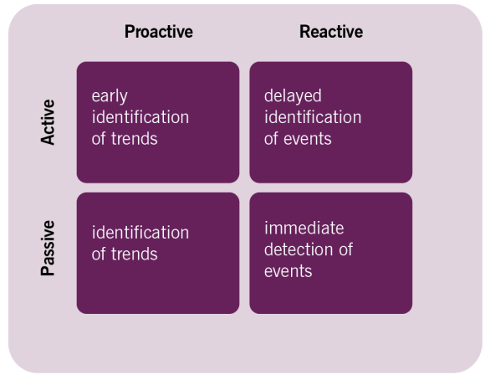
Monitoring and Event Management in ITIL 4
The Evolution of Automation at Google
SRE Principle:
For the enterprising SRE, finding opportunities to automate is the whole point of the job. Site Reliability Engineers don’t need to worry about automating themselves out of work because there will always be something more to improve. The environment is never static hence the work will never be done. And time saved in automation can be dedicated to improving other parts of the environment.
As the book says: “For SRE, automation is a force multiplier, not a panacea. Of course, just multiplying force does not naturally change the accuracy of where that force is applied: doing automation thoughtlessly can create as many problems as it solves. Therefore, while we believe that software-based automation is superior to manual operation in most circumstances, better than either option is a higher-level system design requiring neither of them—an autonomous system. Or to put it another way, the value of automation comes from both what it does and its judicious application. We’ll discuss both the value of automation and how our attitude has evolved over time.”
ITSM Commentary:
Again ITIL 4 as a framework is in alignment with these SRE concepts. There is an entire guiding principle on Optimize and Automate, focused on this specific principle. Likewise, most of the ITIL 4 practices, especially the Service Management and Technical practices, include long sections advocating for the thoughtful use of automation.
At its heart, automation does three profound things.
-
It reduces and/or eliminates toil, making work more satisfying for the people doing it and dialing back on the drudgery associated with it.
-
It reduces the human error that inevitably comes with repetitive work.
-
It makes the output of this work uniform.
The ITIL 4 Digital and IT Strategy publication, in particular, talks about the different levels of automation and how it supports the overall strategy of a digital organization.
I have my own adage that I have been saying for some time now about automation: it makes work repeatable, predictable and, above all, improvable.
Release Engineering
SRE Principle:
Release engineering is one of Google’s “crown jewels” so needless to say, they are very good at it. Google has developed an automated release system called Rapid. Rapid is a system that leverages a number of Google technologies to provide a framework that delivers scalable, hermetic, and reliable releases. Their Release Engineering methodology is defined by these four principles:
Self-Service Model:
- In order to work at scale, teams must be self-sufficient. Release engineering has developed best practices and tools that allow our product development teams to control and run their own release processes. Although we have thousands of engineers and products, we can achieve a high release velocity because individual teams can decide how often and when to release new versions of their products. Release processes can be automated to the point that they require minimal involvement by the engineers, and many projects are automatically built and released using a combination of our automated build system and our deployment tools. Releases are truly automatic, and only require engineer involvement if and when problems arise.
High Velocity:
- User-facing software (such as many components of Google Search) is rebuilt frequently, as we aim to roll out customer-facing features as quickly as possible. We have embraced the philosophy that frequent releases result in fewer changes between versions. This approach makes testing and troubleshooting easier. Some teams perform hourly builds and then select the version to actually deploy to production from the resulting pool of builds. Selection is based upon the test results and the features contained in a given build. Other teams have adopted a “Push on Green” release model and deploy every build that passes all tests.
Hermetic Builds:
- Build tools must allow us to ensure consistency and repeatability. If two people attempt to build the same product at the same revision number in the source code repository on different machines, we expect identical results. Our builds are hermetic, meaning that they are insensitive to the libraries and other software installed on the build machine. Instead, builds depend on known versions of build tools, such as compilers, and dependencies, such as libraries. The build process is self-contained and must not rely on services that are external to the build environment.
- Rebuilding older releases when we need to fix a bug in software that’s running in production can be a challenge. We accomplish this task by rebuilding at the same revision as the original build and including specific changes that were submitted after that point in time. We call this tactic cherry picking. Our build tools are themselves versioned based on the revision in the source code repository for the project being built. Therefore, a project built last month won’t use this month’s version of the compiler if a cherry pick is required, because that version may contain incompatible or undesired features.
Enforcement of Policies and Procedures
Several layers of security and access control determine who can perform specific operations when releasing a project. Gated operations include:
- Approving source code changes—this operation is managed through configuration files scattered throughout the codebase
- Specifying the actions to be performed during the release process
- Creating a new release
- Approving the initial integration proposal (which is a request to perform a build at a specific revision number in the source code repository) and subsequent cherry picks
- Deploying a new release
- Making changes to a project’s build configuration
Almost all changes to the codebase require a code review, which is a streamlined action integrated into our normal developer workflow. Our automated release system produces a report of all changes contained in a release, which is archived with other build artifacts. By allowing SREs to understand what changes are included in a new release of a project, this report can expedite troubleshooting when there are problems with a release.
ITSM Commentary:
The ITIL 4 framework so thoroughly concurs with the importance of this principle to the degree that it includes a publication, course, and exam called High Velocity IT. The HVIT publication covers a number of related topics including Canary Releases, DevSecOps, and CI/CD. ITIL 4 also include specific practices on Release Management and Deployment Management .
While separated in the ITIL 4 publications, the SRE books tend to blend these concepts into Release Engineering. The ITIL 4 framework details the following concepts that translate nicely into SRE:
- CI: Continuous integration refers to integrating, building, and testing code within the software development environment.
- CD: Continuous delivery extends this integration, covering the final stages for production deployment. CD means that built software can be released into production at any time.
- CI/CD: Continuous deploy refers to the changes that go through the process and are automatically put into production. CI/CD enables multiple production deployments a day. Continuous delivery means that frequent deployments are possible, but deployment decisions are taken case by case, usually due to business preferring a slower rate of deployment. Continuous Deployment requires that Continuous Delivery is being done.
As for the Guiding Principles, Release Engineering can be seen to incorporate all of them.
Simplicity
SRE Principle:
Simplicity is an elegant way, on Google’s behalf, to conclude their list of SRE Principles. It is easy to heap on features and complications, which customers may never use. However, achieving real simplicity is hard.
Software simplicity is a prerequisite to reliability. We are not being lazy when we consider how we might simplify each step of a given task. Instead, we are clarifying what it is we actually want to accomplish and how we might most easily do so. Every time we say “no” to a feature, we are not restricting innovation; we are keeping the environment uncluttered of distractions so that focus remains squarely on innovation, and real engineering can proceed.
ITSM Commentary:
The ITIL 4 framework shares the SRE book’s emphasis on simplicity with the Guiding Principle Keep it simple and practical followed closely by Optimize and automate. After some 75 years of creating top-heavy, overly complicated, Rube Goldberg-esque technical IT solutions, the entire industry – with the rise of movements like Agile, DevOps, and others – as well as our customers are starting to understand and delight in the incredible value of simplicity.
Conclusion
I hope you have enjoyed this brief foray into Site Reliability Engineering concepts and the SRE role. Far from competing with other philosophies and frameworks like Agile, DevOps, and IT Service Management, SRE provides organizations with complementary guidance to maintaining reliable, available, and serviceable systems and services to our customers. The borrowing can go in both directions. As a framework for guidance, ITIL 4 explicitly lacks the technology-specific guidance and specifications, rather setting itself as a universally applicable, technology-agnostic set of good practices. However, as cloud-based services and solutions become the norm, we can look to SRE for more technology-focused assistance and specific recommendations.
Ultimately, there’s real value in taking the best from each discipline and incorporating general and specific tools and techniques into bringing value to those we serve, both now and into the future.